The development of waste-to-energy facilities encounters some problems. One of the biggest among them is the cost of an incineration plant. There are so many fairy tales about this business, so many fantastic technologies offered at very low prices. This creates wrong expectations of clients concerning price level. A client should recognize the average price level in the industry before commencing the project.
We recently showed that there is no other reference point for any waste-to-energy technology except the incineration plant. It is the most prevalent and approved thermal treatment technology in the world so far, do you like it or not. Every newly developed facility should be compared with the price of an incineration plant with a similar capacity. But what is the price level of incineration and how does it change with capacity?
Basing on our construction experience and contacts with the world top producers, we understand the cost of an incineration plant. We consider that the following independent research describes the capital cost of the waste-to-energy plant properly. You can download its abstract in pdf from our site. The research contains the following empiric formula:
I = 2.3507×C0.7753,
where I is the investment cost in million dollars and C is the plant capacity (1000 metric tons of waste/year).
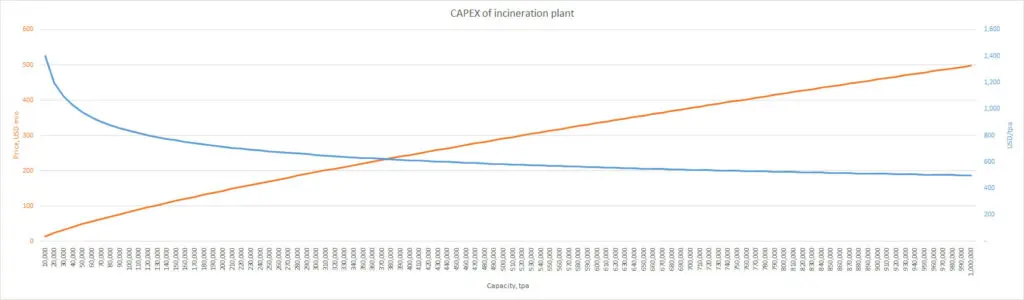
Cost of incineration plant by formula
According to the formula, the cost of a 40,000 tpa plant is $41 million, or $1,026 per ton of annual capacity. A Medium-sized 250,000 tpa plant should cost $169 million, or $680 per ton of annual capacity. These numbers give us the first estimation of how much waste-to-energy is. Additionally, there is quite adequate dependence of CAPEX per ton of annual capacity on the capacity by itself (blue curve).
Here is the simple calculator allowing to get values for a certain annual capacity.
We should understand that the formula describes the cost of incineration plant relates to municipal solid waste (MSW) to electricity plants. However, it can vary depending on the technology implemented – it could be burning on the grate or the fluidized bed. Hazardous medical and industrial waste processing costs significantly more. They require rotary kiln technology for big volumes and even more sophisticated flue gas cleaning systems.
There is a lot of talking on the market concerning the price of waste-to-energy facilities. Many companies making attractive offers, but they all have one problem – nothing works. The client should ask low-cost bidders to show what do they have under commercial operation. And upon the predictable answer, return to commercially approved technologies. No matter what is it: pyrolysis, gasification, incineration or plasma treatment – price deviation from the above will be no more than +-50%.
It is the market. No miracles here.
Update
We unveiled the online service for evaluation of the financial feasibility of a waste-to-energy power plant. If you know the input parameters of your proposed plant, you can request financial modelling by the link below.





We are planning to open waste to energy (household waste from landfil) , can you give me further information on equipment’s required, cost , land size etc.
Thank you for your comment.
If you are referring to old household waste already deposited in a landfill, it is not a feedstock for a conventional waste-to-energy plant, as its calorific value has already been degraded.
Waste-to-energy projects are normally developed around a stable stream of freshly generated municipal solid waste with known daily volume and composition.
If you have access to a fresh municipal waste stream (for example, from a city, municipality, or collection operator), we can support with a paid pre-feasibility assessment covering the recommended process route, key equipment blocks, CAPEX range, and land requirement.
Please feel free to contact us via the website form, specifying the project country and expected tons per day.
Dear Igor
Hello
We are planning to burn industrial wastes in the form of slurry in a rotary kiln. Our required capacity is 1000 kg/h. How much will the equipment cost with the above dust collection system without power generation equipment?
thanks.
Hello Shayan,
I have answered via email.
Many thanks.
Hello! Mr. Igor Gergel !
I think your formula is very reasonable. It is really useful to estimate the cost for WTE plant.
My company is a company which supply wte system facility.
So, I would like to know what percentage of the cost is allocated to system facilities(incinerator, burner, turbine and generator), construction, installation, and others.
Of course, it is difficult to estimate exactly the each part of cost since its situation is so different according to the land, country, human labor etc. But I want to get just approximate data.
I hope your quick reply.
Thank you very much!
Lee, Kisong in Korea.
(my company is TGEP)
Hello Lee,
I have answered via email.
Many thanks.
I would be very thankful to give me information about How much does the municipality cost to build a 1000 ton per day waste-incineration plant for the year 2024
With best regards
Choobdar.E
Hello,
You can use our calculator above in the article.
Dear Igor
This formula to calculate the CAPEX was published in 2015. I am worried about whether the formula would be accurate to use in 2024, as various conditions such as inflation, and rise in prices of machines are to be considered. And can i use this formula to calculate the CAPEX for a pre-feasibility study on waste-to-energy conversion?
Dear Rajesh,
Yes, you are right – it was published years ago. But we have two counter processes: inflation and reduction of the equipment cost. So, the formula remains valid now not only in the sense of the curve, but more or less following absolute numbers for the EU producers.
I kindly request a quotation for the 160MW Waste to Energy Plant.
The quotation for the plant can be done upon the feasibility study only. It is a costly and time consuming process. You can use calculator in the article to estimate the cost.
Igor,
Can we put coal in your conversion equipment, extract Bio Diesel, then reuse the coal in our power plant@ a higher BTU burn?
Thanks,
Pat
Pat,
You can put coal into pyrolysis equipment and extract bio-diesel. It is impossible to re-use coal after pyrolysis, as it converts its energy into diesel.
Interested, it seems we can discuss further via email
Excelente tecnología.
I’m intrested in your wte solutions for one of my clients in the gulf region, please provide with contact information for one of your experts to discuss further…
Dear Anise Jarrar,
Thank you for writing to us. I have answered via email.
Would you like to build base to energy power plan in Philippine you’d like to know what do you need from us thank you
Dear Bruce,
Thank you for contacting us. We are interested to cooperate with you in the Philippines. I have answered in detail by email.
I am evaluating the utility of hydrothermal processing of MSW to produce an engineered fuel pellet, technology similar to Hokuto Kougyo Co.(Hokuto) of Japan. Are you familiar with this process technology and offer consulting services for new entries into this space?
Dear Travis,
We can provide consulting services for a variety of waste processing applications. Could you please ask your questions via our email?
Hi, can you’re technology be used to include hydrogen as a secondary raw material?
The tire pyrolysis technology?
We can process tires. Please read our article “ENCORE Advanced Pyrolysis Technology“.
Hi Boris,
Yes, in general, we can produce hydrogen from the waste.
Hi! I am Thuy from Vietnam. Now I am doing my exercise as how to calculate the variable cost of a WtE power plant. I am very confused. Could you please kindly suggest any idea?
Hi Thuy,
You can estimate annual operating expenses (OPEX) as 5-10% of the CAPEX of the plant.
My name is Jessie Barber. I am writing a paper in school about the problems of a nearby landfill. My solution to fix this problem would be to build an incinerator. I am not very knowledgeable about incinerators overall. I have been reading a lot about these services and I hoped you give give me some information that could help me report. The landfill is located in Bristol VA in an old quarry. Thank you for your time.
Hi Jessie,
You can use the information on our website:
https://wteinternational.com/news/waste-to-energy-technologies-overview/
https://wteinternational.com/news/cost-of-incineration-plant/
https://wteinternational.com/solutions/pyrolysis/encore-advanced-pyrolysis-technology/
https://wteinternational.com/projects/landfills/
I hope this can help with your study.
Hi. I am based in South Africa and I am interested on establishing an incinerator plant to address the challenge we are facing regarding hazardous waste. Could you please help.
Thank you
We can work with South Africa. For more information, please reach us by email.
Thank you.
Dear Sir,
Thank you for sharing your very useful knowledge about Waste to Energy. I am studying waste to energy plant now.
I would like to ask for some information regarding the ratio regarding capex and Opex related to Waste to Energy Plants.
Does the capex also include land acquisition costs?
What is the % of the cost for Civil Work to the total Capex?
What is the % of repair & maintenance costs to the Capex and also to The Opex.
How much is cost of chemical, is it better to compare % of chemical cost to the opex or capex ?
Thank You
Dear Fuad,
Below are answers to your questions.
OPEX per annum rarely exceed 5% of the CAPEX.
CAPEX does not include land lease costs. Anyway, land lease costs are incomparable with the CAPEX.
Civil works make up 30-50% of the CAPEX depending on the plant type and the technology.
Detailisation of the OPEX to chemicals and repairs is not needed to determine the plant efficiency and is subject to the O&M agreement with the specialised company.
I like your website, we should discuss deals in Latin America, and maybe later in Canada/USA
Thank you. We are interested in Latin America and will answer you by email.
I want to open this type of plant in my state ..Odisha,India .
Can you help me
Please read the article concerning investments https://wteinternational.com/services/investments/alternative-energy-investments/ and fill out our Project Questionnaire https://wteinternational.com/contact/project-questionnaire-waste-to-energy/.
Our team will be happy to help.
I am a representative of a company here in Nigeria. We seek for a partner in establishing a waste to energy plant in Lagos State, Nigeria. Lagos city is one of the largest cities in Africa and densely populated too. The land is congested hence waste management is one of the most important environmental issues here. Currently, the landfill sites are getting closed up due to lack of land and as such, WTE plant/incinerator is considered a lucrative option.The State government is interested in PPP towards creating a facility. Based on your experience, could you be willing to introduce to us potential firms/partners. We seek for one urgently as we are about preparing our proposal and feasibility studies. Thanks!
Thank you, Mr Newman.
We are interested in Nigeria and will answer you by email.
Hello sir can please get estimation for biogas project
We plan to write articles about the cost of biogas and pyrolysis plants. Would you please subscribe to our news on the archive page: https://wteinternational.com/news/category/company/?
Where can I get a chinese company to fix it ? Any recommendations
To fix what?
Hi Sir
I’m in Africa I need the waste to energy that can power more than 20,000 House per day how much does it cost
It depends on the chemical composition, HHV of the municipal solid waste and its moisture. A specialized developer should calculate the energy which can be extracted from 1 ton of MSW and compare it to the energy requires for homes. In this way, you can estimate the capacity of a waste-to-energy plant. Then, derive it preliminary cost estimation using the formula above.
Thank you so much for your reply, so where can I find a A specialized developer that can do that for us and how can we work together in this project
Our company is such a developer. We can do it during the feasibility study. Please explain your case by email which can be found on the Contacts page.
Hello,
1 – Do the costs above include for design fees and owner delivery / project management fees, statutory approval fees and the like, owners development contingency etc. or are they construction costs only?
– EG are the cost below deemed to be ‘EPC turnkey’ costs or do additioanl costs need to be added when doing high level calcs?
– Which location are the above costs based on? Ex US?
Thank you
Hello Jodi,
The costs above show the plant CAPEX: i.e., turn-key price.
Location does not affect costs too much, you can consider costs as a world-average.
Hi
I have received a turnkey offer of 234 million USD to build a 2600 ton/day WTE plant generating around 70 MW , it looks too good to be true according to your figures , any comments ?
Regards
Mohammed Majid
Hi Mohammed,
It depends on several factors: the strength of the EPC provider, location, waste quality. Cost estimation provided here in the article is the world average. We can construct plants significantly cheaper due to deep knowledge of the market and experience.
Not to disclose sensitive information, let us continue this dialogue via email. We will write to you and share some thoughts privately.
Best regards,
WTEI team.
Hello:
Thanks for all the useful information and the useful Cost Calculator (not sure why other comments didn’t just use it). Questions are as follows:
Is the cost from the calculator a total project (inclusive of design, CA, PM, etc.) or just a construction cost?
I noticed that the web page is from 2015 so is the cost calculator generating 2015 costs that I should escalate to my actual construction date? Please define year of costs.
Thanks
Hello Mr Coffee,
Thank you for your comment.
Cost calculator and formula estimate the total world-average turn-key cost of the plant (CAPEX).
From 2015, price estimation has not changed. Whilst the costs of materials and equipment escalate due to inflation, the total cost of the technology goes down due to mass production. So, estimations are still actual.
And we as WTEI can construct the plant significantly cheaper (as we have the real practical experience and good knowledge of the market).
Hi WTE,
The calculator formula seems to assume the incinerator plant will have a Power generation plant attached to it. How is the formula affected if the plant is just for the Incinerator WITHOUT the electricity generation component
What is the use of just incineration? How to return investments?
I would like to know what it would cost to set up a waste to energy incineration plant with capacity of 100 tpd combustion, how many mWh such an undertaking would generate and how long it would take to construct.
It highly depends on waste composition and moisture. For 100 tpd plant (which is very small size of the plant), typical electricity production could be 1.5 MW.
i have a research about MSW and i want to know more about waste to energyy,, what is the size of one incineration plant? like dimensions? if there are many types perhaps could u tell me the average? because im designing a waste to energy facility as a task since im an engineering student.. please help me 🙂
Very roughly typical land needed is 2 ha per each 100,000 ton of annual capacity.
How can i find data that related to capital cost and maintenance cost of plastic incineration ?
Data on capital cost (CAPEX) is here in the calculator. Maintenance cost is approximately 5-10% from CAPEX annually. You can request calculation of the plant on the Waste-to-Energy Model page.
I am not sure I’m getting the calculation right but I want just a 1 ton/hour but I got just about $600k.
Could you point to a company which makes that capacity?
1 ton per hour means some 8,000 ton per year. Calculator above will show 12 million USD,
As it is said in the article, for such small capacities, price per ton raises rapidly. That is why we have such a big number.
The formula discussed works well for capacities starting from 50,000 tpa, as it covers market of big incinerators.
If you want incinerator for 1 ton per hour, we can provide it for you. Please fill out the form https://wteinternational.com/development/project-questionnaire/ or just describe your project details by email to [email protected]
Thank you.
Dear Mr Arslan,
You can use calculator in this post to get first estimation of total cost. Economy efficiency calculations can be ordered for EUR 599 on our page https://wteinternational.com/development/financial-model/waste-to-energy-model/.
Detailed cost breakdown for the plant is a part of feasibility study, which we can perform on a contract basis.
Hello,
i need an estimation of Incineration plant to process 200000 tpa of MSW, for energy generation. It will be more helpful if this cost is properly breaked-down into all components of, CAPEX & OPEX.
BR,
MUHAMMAD ARSLAN
Usually annual operating and maintenance cost of the incineration plant is 5-7% of total construction cost..
HI, Is there a rule of thumb on the ration of operation cost and maintenance cost over construction cost? For example WTE plant of 1200t/d
Hi, does this your formula give the price of the entire components of the Integrated Waste Management system or only the incinerator compotent.
This is the cost of incinerator plant, including all its infrastructure: presorting facility, incineration, flue gas cleaning system, energy generation, buildings etc.
Integrated Waste Management system for a city includes waste collection, logistics, sorting, incineration plant, landfilling. It is a bigger system. Main cost in it has, however, incineration plant.
I need a Waste to energy incineration plant with an annual capacity of 127,750 tons
What is the costs of establishing such a plant?
You can use our calculator. Put into it 127750 and you will have USD 101 million.
Hello. First of all, you can use our calculator on the right. If you want to calculate manually for 100,000 tpa plant, then please take into account that C=100 (capacity in 1000 metric tons of waste/year). So, formula is
I = 2.3507×100^0.7753
I = 83.5 (in million USD)
So, CAPEX of a typical 100,000 tpa MSW incineration plant is 83.5 million USD.
You can request calculation of the financial model of your plant online: https://wteinternational.com/development/financial-model/waste-to-energy-model/
or hire us for consulting, development of feasibility study, construction supervision, etc.
Hello. I tried to compute investment cost manually using the provided formulae (for a 100,000 tpa plant). I’m getting a pretty different cost. Are there additional variables factored in?
We are ready to support you on the basis of paid consulting or full development cycle. Please fill out Partner Questionnaire Form on out site https://wteinternational.com/development/partner-questionnaire/ and we will return with our standard NDNCA.
Good day, I want to invite a Waste to Energy company to come invest in my community that boasts over 3million homes, offices and large markets with a lot of unused waste lying everywhere. I like the incinerator technology as it would get rid of the excess waste. Please, what Chinese Producers would you advise I contact for that. Thanks
All European brands are on more or less same price level. The final cost of such a complicated facility as waste-to-energy plant depends on many factors:
– location country
– type of incineration technology selected
– usage of periperal equipment such as generators, boilers, etc. by local suppliers
– architectural solutions
– waste composition and moisture, and so on.
So there is no simple answer to your question. Final total cost of the plant can be properly estimated only during the feasibility study process.
Which are the best cost-benefit European brand?
In waste-to-energy sector, the less expensive technology (per ton of annual capacity) is incineration, due to a huge number of installations and long history. There are a number of producers, European are most reputable and more expensive. Some Chinese producers offer today relatively cheaper incineration equipment conforming, however, to all modern ecological standards.
Encore technology is mostly for tires, rubber, plastic, sludge etc. and, as other pyrolysis equipment, it is a bit more expensive than incineration.
Actual prices we disclosure only for certain solid project upon signing of NDNCA.
what is the exact figure for the Encore advanced pyrolysis tech plant? what is the most inexpensive project/ plant?